
はじめに
Azure Data Factory (ADF) を使ってデータを効率的に処理する方法の一つに「条件分割」があります。この記事では、ADF初心者向けに、条件分割の基本的な概念と実際の手順を詳しく解説します。条件分割を活用することで、データのフィルタリングや特定の条件に基づいた処理が容易になります。この記事を読むことで、ADFを使ったデータ処理のスキルを向上させ、実務に役立てることができるでしょう。
条件分割アクティビティとは?
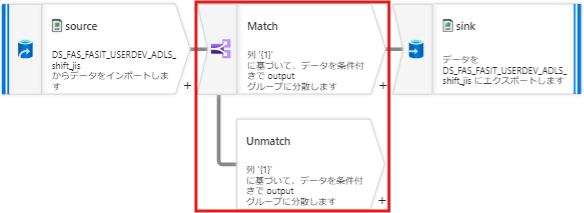
条件分割アクティビティは、データ行を特定の条件に基づいて異なるストリームにルーティングするための機能です。
プログラミング言語のCASE文に似ており、各データ行が指定された条件に一致するかどうかを評価し、その結果に基づいてデータを異なる出力に振り分けます。
主な特徴
- 条件評価: 各データ行に対して条件を評価し、一致するストリームにデータを送ります。
- 複数条件の設定: 複数の条件を設定でき、最初に一致した条件に基づいてデータを振り分けるか、すべての一致条件に基づいて振り分けるかを選択できます。
- デフォルトストリーム: いずれの条件にも一致しないデータ行を処理するためのデフォルトストリームを設定できます。
データ内容
今回使う入力データの内容は以下の通り。
入力内容
データの内容
分割する source.csv です。output の値を判断してファイルを分割します。
この記事では、このデータを基に「output が 150 以下のデータ」と「output が 150 より大きいデータ」を分割する条件分割の方法を解説します。
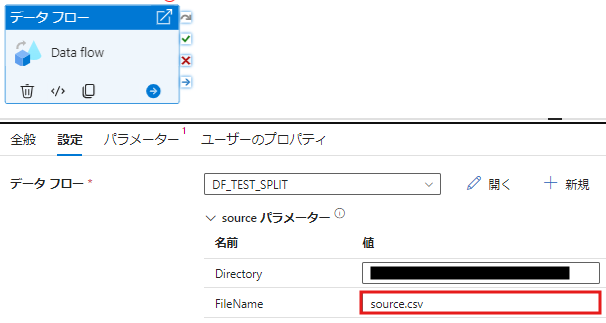
source.csv
| type | base | date | output |
|---|---|---|---|
| A | X | 2024/12/01 | 150 |
| B | Y | 2024/12/02 | 200 |
想定結果
条件「output <= 150」にマッチしたデータと、アンマッチしたデータ
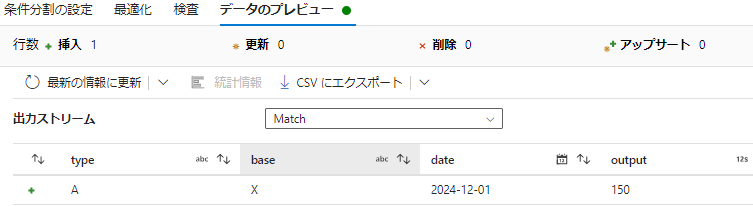
条件にマッチしたデータ
| type | base | date | output |
|---|---|---|---|
| A | X | 2024/12/01 | 150 |
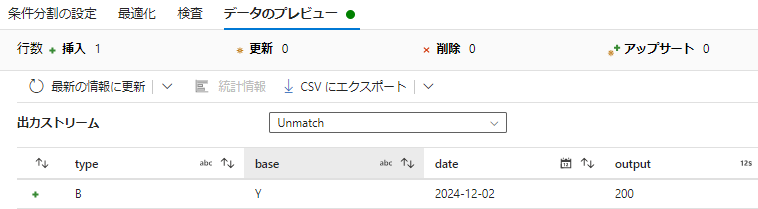
条件にアンマッチしたデータ
| type | base | date | output |
|---|---|---|---|
| B | Y | 2024/12/02 | 200 |
処理手順
1. データセットの作成
- ADFポータルにログインし、新しいデータセットを作成します。
- source.csv のデータセットをそれぞれ作成し、適切なリンクサービスを設定します。
データセットの作り方は以下の投稿で説明。
2. パイプラインの作成
- 新しいパイプラインを作成し、データフローアクティビティを追加します。
- データフローの中で、ソースとして source.csv を追加します。
3. 条件分割アクティビティの追加
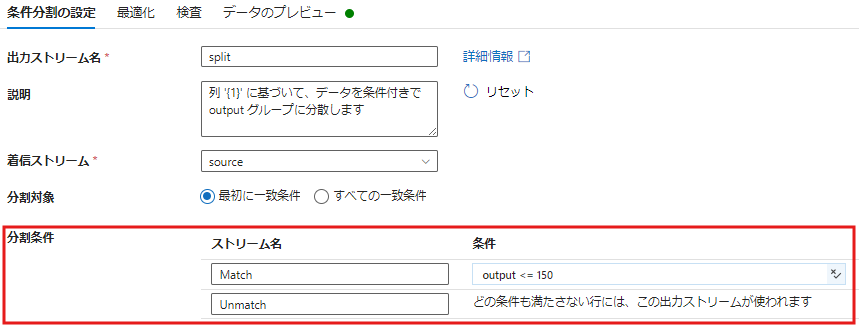
- データフロー内で条件分割アクティビティを追加し、source.csv を分割します。
- 分割条件として以下の通り設定します。
- ストリーム名「Match」が「output <= 150 (outputが150以下)」
- ストリーム名「Unmatch」が「どの条件も満たさない行には、この出力ストリームが使われます」
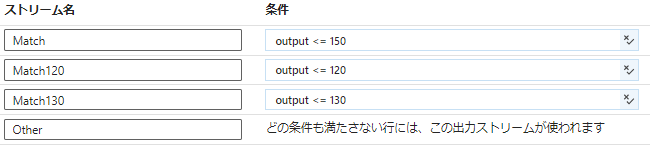
プログラム言語のCASE文のように使えるので、以下のように複数の条件を指定可能です。
4. 出力の確認
- 「データのプレビュー」でデータを確認します。
- 「出力ストリーム」のプルダウンから出力先を選択して表示させられます。
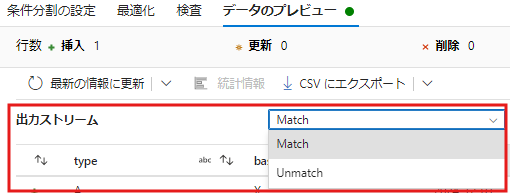
Matchの出力
Unmatchの出力
5. データの変換
- 必要に応じて、データの変換アクティビティを追加し、分割後のデータを整形します。
まとめ
この記事では、Azure Data Factoryを使った条件分割の基本的な手順を解説しました。条件分割を活用することで、特定の条件に基づいたデータ処理が容易になり、データの管理や分析が効率化されます。
ADFを使いこなすことで、データエンジニアリングのスキルを向上させ、より高度なデータ処理が可能になります。
ぜひ、この記事を参考にして、ADFでのデータ処理を実践してみてください。


コメント