
はじめに
ファイルの結合は、データ統合の基本的な作業の一つです。Azure Data Factory (ADF) を使用すると、複数のデータソースからのファイルを簡単に結合し、効率的にデータを処理することができます。本記事では、ADFを使ってファイルを結合する具体的な手順を詳しく解説します。初心者でも理解しやすいように、ステップバイステップで説明しますので、ぜひ参考にしてください。
結合アクティビティとは
Azure Data Factoryの結合アクティビティは、マッピングデータフロー内で2つのデータソースやストリームを結合するために使用されます。これにより、異なるデータソースからのデータを統合し、分析や処理を行うことができます。

結合の種類
Azure Data Factoryでは、以下の5種類の結合がサポートされています

- 内部結合:両方のテーブルで値が一致する行のみが出力されます。
- 左外部結合:左側ストリームのすべての行と、右側ストリームで一致するレコードが返されます。左側に一致するものがない場合、右側の出力列はNULLになります。
- 右外部結合:右側ストリームのすべての行と、左側ストリームで一致するレコードが返されます。右側に一致するものがない場合、左側の出力列はNULLになります。
- 完全外部結合:両方の側のすべての列と行が、一致しない列にはNULL値を使用して出力されます。
- カスタムクロス結合:条件に基づいて2つのストリームのクロス積が出力されます。非等結合やOR条件に使用できます。
データ内容
今回使う入力データの内容は以下の通り。
入力内容
データの内容
結合する source.csv と target.csv です。「type」と「base」をキーとして、data と outpu の情報を結合します。
本記事では、このデータを例にして、ADFでのファイル結合方法を説明します。
source.csv
| type | base | date | output |
|---|---|---|---|
| A | X | 2024/12/01 | 150 |
| B | Y | 2024/12/02 | 200 |
target.csv
| type | base | date | output |
|---|---|---|---|
| A | X | 2024/12/01 | 100 |
| C | Z | 2024/12/03 | 300 |
想定結果
それぞれ「完全外部」「内部」「左外部」「右外部」「カスタム(クロス)」で結合した想定結果です。
「完全結合」した結果
source.csv と target.csv の一致する行、一致しない行すべて
| type | base | date | output |
|---|---|---|---|
| A | X | 2024/12/01 | 150 |
| B | Y | 2024/12/02 | 200 |
| null | null | null | null |
| type | base | date | output |
|---|---|---|---|
| A | X | 2024/12/01 | 100 |
| null | null | null | null |
| C | Z | 2024/12/03 | 300 |
「内部結合」した結果
source.csv と target.csv の一致する行のみ
| type | base | date | output |
|---|---|---|---|
| A | X | 2024/12/01 | 150 |
| type | base | date | output |
|---|---|---|---|
| A | X | 2024/12/01 | 100 |
「左外部結合」した結果
source.csv 側から一致した行、一致しない行
| type | base | date | output |
|---|---|---|---|
| A | X | 2024/12/01 | 150 |
| B | Y | 2024/12/02 | 200 |
| null | null | null | null |
| type | base | date | output |
|---|---|---|---|
| null | null | null | null |
| null | null | null | null |
| C | Z | 2024/12/03 | 300 |
「右内部結合」した結果
target.csv 側から一致した行、一致しない行
| type | base | date | output |
|---|---|---|---|
| A | X | 2024/12/01 | 150 |
| null | null | null | null |
| type | base | date | output |
|---|---|---|---|
| A | X | 2024/12/01 | 100 |
| C | Z | 2024/12/03 | 300 |
「カスタム(クロス)結合」した結果
よくわからんので、お勉強したら書きます。
処理手順
1. データセットの作成
- ADFポータルにログインし、新しいデータセットを作成します。
- source.csv と target.csv のデータセットをそれぞれ作成し、適切なリンクサービスを設定します。
データセットの作り方は以下の投稿で説明。

2. パイプラインの作成
- 新しいパイプラインを作成し、データフローアクティビティを追加します。
- データフローの中で、ソースとして source.csv と target.csv を追加します。
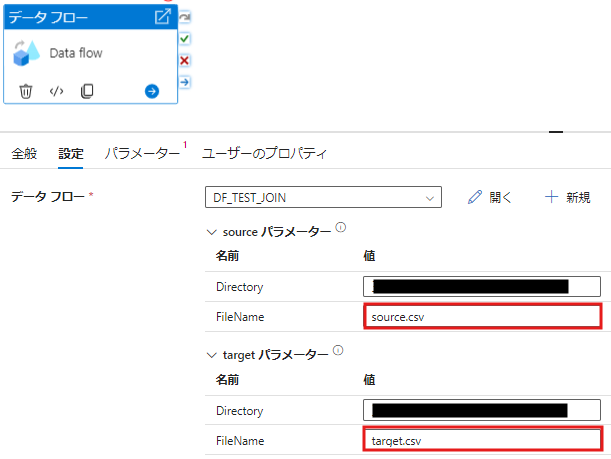
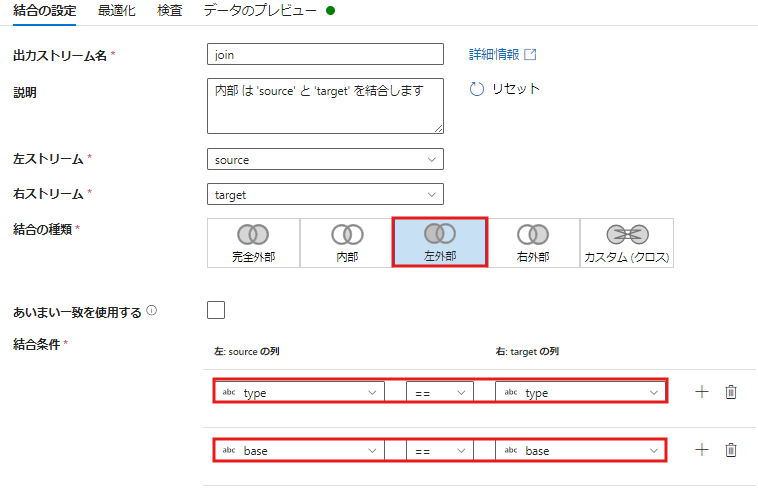
3. JOINアクティビティの設定
- データフロー内でJOINアクティビティを追加し、source.csv と target.csv を結合します。
- 結合キーとして「type」と「base」を設定し、結合タイプを選択します(例:左外部結合)。
4. データの変換
- 必要に応じて、データの変換アクティビティを追加し、結合後のデータを整形します。
- 例えば、NULL値の処理やデータ型の変換を行います。
5. 出力データの確認
- 「データのプレビュー」でデータを確認します。

まとめ
Azure Data Factory の「結合」を使用することで、複数のファイルを簡単に結合し、効率的にデータを処理することができます。
本記事で紹介した手順を参考に、ぜひADFを活用してみてください。
ファイル結合のプロセスを理解することで、より高度なデータ統合作業にも挑戦できるようになるでしょう。


コメント