
はじめに
Azure Data Factory (ADF) の既存アクティビティは、データの存在確認を効率的に行うための機能です。
本記事では、既存アクティビティの基本的な使い方とその利点について詳しく解説します。データの存在確認は、データパイプラインの信頼性を高めるために欠かせないステップです。この記事を通じて、既存アクティビティを活用し、データ処理の精度を向上させましょう。
とは言いつつ、業務で使ったことはまだない。
ファイル同士を当てて、差分を出すときに使うんだよね。
既存アクティビティとは?
既存アクティビティは、データフロー内で特定のデータが他のデータソースやストリームに存在するかどうかを確認するための変換アクティビティです。このアクティビティは、SQLの WHERE EXISTS および WHERE NOT EXISTS に似た動作をします。
主な機能
- 行フィルタリング: 左側のデータストリームにある行が右側のデータストリームに存在するかどうかをチェックします。
- 存在タイプの設定: データが存在するか、存在しないかを指定できます。

- カスタム条件: 比較するキー列を指定し、複数の条件を追加することができます。

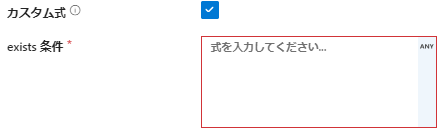
使用例
例えば、製品番号が異なる2つのデータストリームを比較する場合、以下のように設定します:
- 左側のデータストリームの製品番号と右側のデータストリームの製品番号が一致するかどうかを確認して出力します。
データ内容
今回使う入力データの内容は以下の通り。
データの内容
存在確認する source.csv と target.csv です。「type」と「base」をキーとしてデータを比較して存在確認します。
本記事では、このデータを例にして、ADFでの確認方法を説明します。
source.csv
| type | base | date | output |
|---|---|---|---|
| A | X | 2024/12/01 | 150 |
| B | Y | 2024/12/02 | 200 |
target.csv
| type | base | date | output |
|---|---|---|---|
| A | X | 2024/12/01 | 100 |
| C | Z | 2024/12/03 | 300 |
想定結果
source.csv 側に対して、target.csv のデータが存在するのか、存在しないのかを確認します。
「既存」のレコード
A, X は両方に存在する

| type | base | date | output |
|---|---|---|---|
| A | X | 2024/12/01 | 150 |
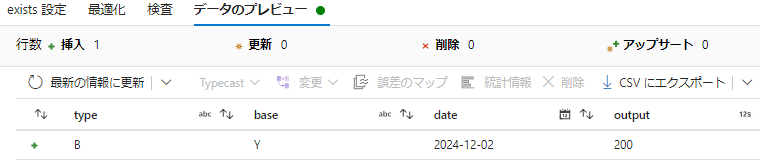
「存在しない」しない
B, Y は target.csv に存在しない

| type | base | date | output |
|---|---|---|---|
| B | Y | 2024/12/02 | 200 |
処理手順
1. データセットの作成
- ADFポータルにログインし、新しいデータセットを作成します。
- source.csv と target.csv のデータセットをそれぞれ作成し、適切なリンクサービスを設定します。
データセットの作り方は以下の投稿で説明。
2. パイプラインの作成
- 新しいパイプラインを作成し、データフローアクティビティを追加します。
- データフローの中で、ソースとして source.csv と target.csv を追加します。
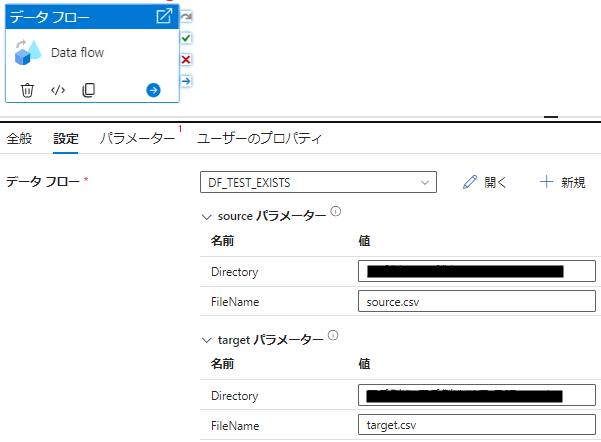
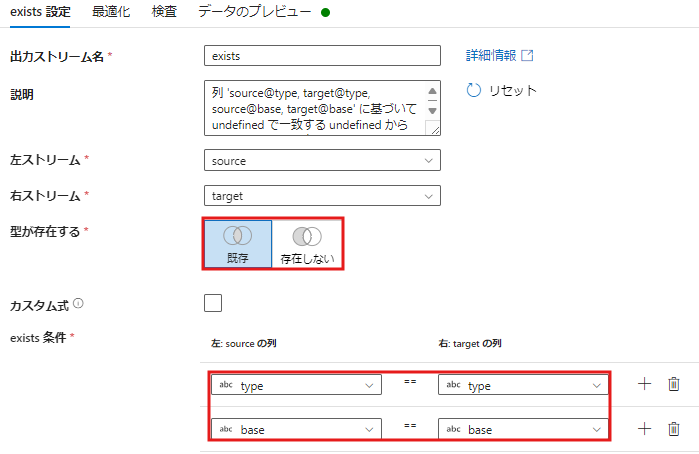
3. 既存アクティビティの設定
- データフロー内で既存アクティビティを追加し、source.csv と target.csv を差分比較します。
- exists条件として「type」と「base」を設定し、”型が存在する”で「既存」選択します。
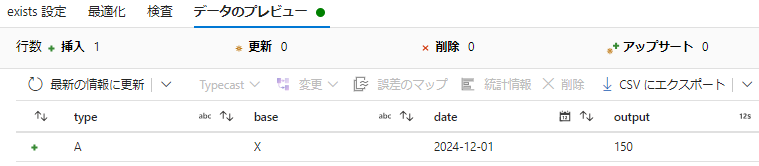
4. 出力データの確認
- 「データのプレビュー」でデータを確認します。
- “型が存在する”で「存在しない」にした場合
まとめ
Azure Data Factory の「既存」を使用することで、複数のファイルを簡単に比較し、存在確認をすることができます。
本記事で紹介した手順を参考に、ぜひADFを活用してみてください。
ファイルの差分比較のプロセスを理解することで、より高度なデータ統合作業にも挑戦できるようになるでしょう。


コメント