
データ処理や統合の場面では、複数のファイルを1つにまとめたり、更新が必要な場合があります。
この記事では、ファイルマージの基本的なシナリオを取り上げ、次のような要件をADFでどのように実現するかを詳しく解説します。
- マージ元とマージ先のデータをキー項目で比較
- 一致するレコードは更新(Update)
- 一致しないレコードは追加(Insert)
これを読めば、ADFでのファイルマージに必要な手順を自分で再現できるようになるでしょう。
それでは、実際のデータセットを使って具体的な手順を見ていきましょう!
マージの要件
- ファイルレイアウト
type, base, date, output
- キー項目
type,base,date
- 処理内容
- キー項目が一致するレコードがマージ先ファイルに存在する場合 → Update
- キー項目が一致しない場合 → Insert
1. データの準備
- マージ元ファイルとマージ先ファイルを Azure Blob Storage にアップロードします。
- ファイル形式は CSV または Parquet を想定します。
例: マージ元ファイル (source.csv)

例: マージ先ファイル (target.csv)

想定結果
- target.csv の 1行目 (A, X) を 150 で更新
- source.csv の 2行目 (B, Y) を 新規追加
- target.csv の 2行目 (C, Z) は そのまま
となる想定。
2. ADF パイプラインの作成
- データフローの作成
- ADF で新しい データフロー を作成します。
- マージ元ファイル(source)とマージ先ファイル(target)の 2 つのソースを設定します。
- キー項目でのマッチング

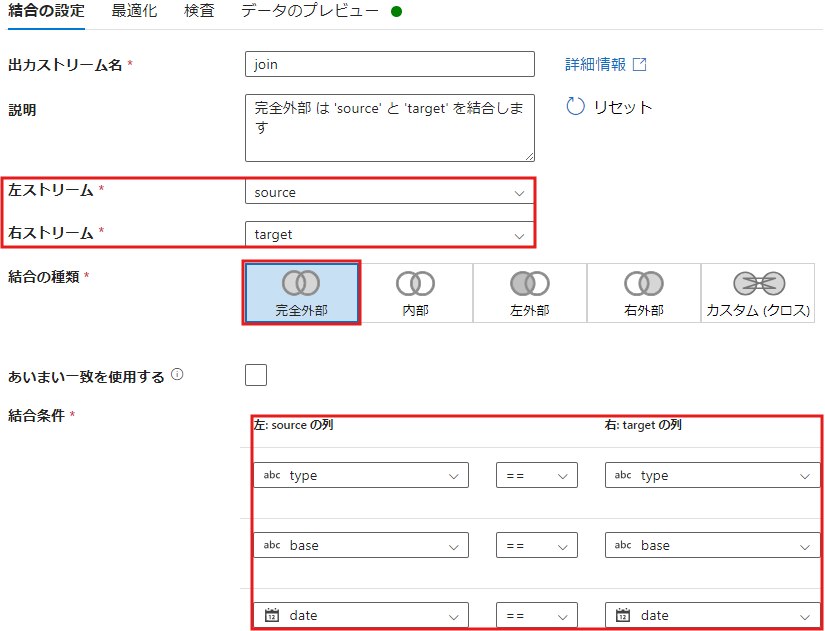
- 結合 アクティビティを使用して、
type,base,dateをキーとして結合します。 - 左ストリーム:source
- 右ストリーム:target
- 結合の種類:完全結合
- 結合条件:
source.type = target.typesource.base = target.basesource.date = target.date
- 結合 アクティビティを使用して、
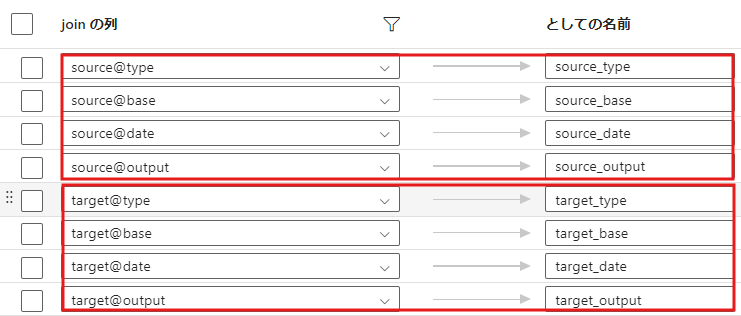
- 列名を変更

- 選択 アクティビティを使用して、それぞれtargetの列なのか、sourceの列なのかがわかるように変更します。
- マージロジックの実装
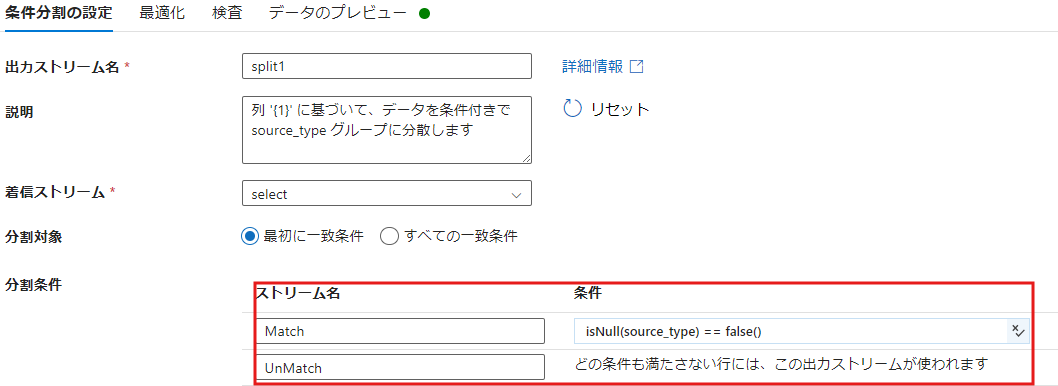
- 条件分割 を使用して、次の 2 つに分けます。

- Match: キー項目が一致するレコード【Update 対象: Source のレコード】
isNull(source_type) == false() - UnMatch: キー項目が一致しないレコード【Insert 対象: target のレコード】
「どの条件も満たさない行には、この出力ストリームが使われます」
- Match: キー項目が一致するレコード【Update 対象: Source のレコード】
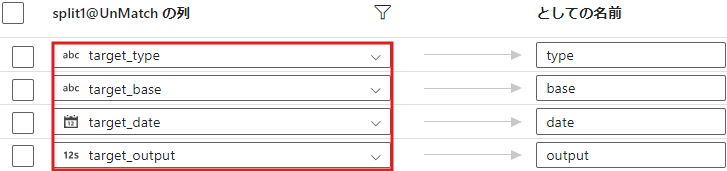
- 条件分割 を使用して、次の 2 つに分けます。
- 列名を変更


- それぞれ Match と UnMatch の列名を元に戻します。
- ターゲットファイルの生成
- Update と Insert の結果を 共用体 アクティビティで結合し、最終的なマージ結果を生成します。

3. 実行結果
マージ後のファイル

4. まとめ
Azure Data Factory のデータフローを使えば、ファイルのマージ処理を視覚的に設定できます。
この記事の例を参考に、業務シナリオに合わせた柔軟なデータ統合を試してみてください!
フロー図の流れ
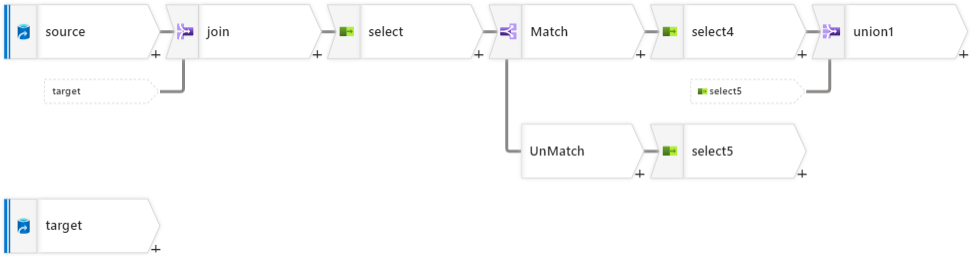
こんな感じ


コメント