
はじめに
異なるデータソースからのデータを一つにまとめることは、データ分析やビジネスインテリジェンスにおいて不可欠です。
本記事では、Azure Data Factoryを使用して、共用体(union)を利用してデータを連結する方法について詳しく説明します。
これにより、複数のデータセットを効率的に統合し、分析に役立てることができます。
共用体アクティビティとは?
複数のデータストリームを一つにまとめるための変換アクティビティです。
このアクティビティを使用すると、異なるデータソースからのデータを結合し、単一の出力として処理することができます。
主な機能
- 複数のデータストリームを結合: Unionアクティビティは、SQLのUnion操作と同様に、複数のデータストリームを一つにまとめます。これにより、異なるデータソースからのデータを統合することができます。
- スキーマの自動統合: 各入力ストリームのスキーマが自動的に統合されるため、共通の結合キーを持つ必要がありません。

- 柔軟な設定: Unionアクティビティでは、名前による結合(union by name)や位置による結合(union by position)を選択できます。名前による結合では、各カラムの値が対応するカラムに配置され、位置による結合では、各カラムの値が元の位置に配置されます。
単純にくっつけるだけだし、設定箇所が少ない!
データ内容
今回使う入力データの内容は以下の通り。
データの内容
連結する source.csv と target.csv です。基本的に同じ列定義で、source.csv の 下に target.csv を単純にくっつけるイメージ。
本記事では、このデータを例にして、ADFでの連結方法を説明します。
source.csv
| type | base | date | output |
|---|---|---|---|
| A | X | 2024/12/01 | 150 |
| B | Y | 2024/12/02 | 200 |
target.csv
| type | base | date | output |
|---|---|---|---|
| A | X | 2024/12/01 | 100 |
| C | Z | 2024/12/03 | 300 |
想定結果
source.csv に対して、target.csv のデータを連結するだけです。
ほんと単純にくっつけただけですね。
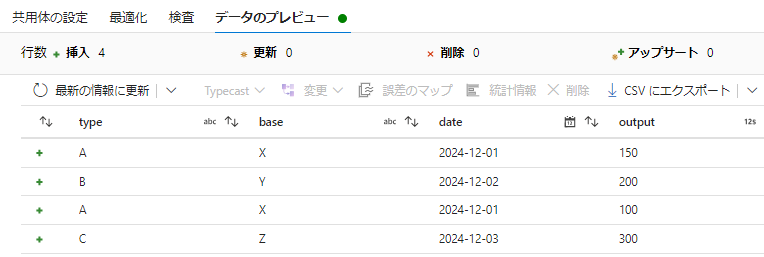
| type | base | date | output |
|---|---|---|---|
| A | X | 2024/12/01 | 150 |
| B | Y | 2024/12/02 | 200 |
| A | X | 2024/12/01 | 100 |
| C | Z | 2024/12/03 | 300 |
設定手順
1. データセットの作成
- ADFポータルにログインし、新しいデータセットを作成します。
- source.csv と target.csv のデータセットをそれぞれ作成し、適切なリンクサービスを設定します。
データセットの作り方は以下の投稿で説明。
Azure Data Factoryで汎用的なデータセットの作り方 | 技術的なメモ書き
2. パイプラインの作成
- 新しいパイプラインを作成し、データフローアクティビティを追加します。
- データフローの中で、ソースとして source.csv と target.csv を追加します。

3. 共用体アクティビティの設定
- データフロー内で共用体アクティビティを追加し、source.csv と target.csv を連結します。
- 結合対象として「target」を選択します。

4. 出力データの確認
- 「データのプレビュー」でデータを確認します。
まとめ
Azure Data Factoryを使用して共用体(union)でデータを連結する方法について解説しました。
この手法を用いることで、異なるデータソースからのデータを効率的に統合し、分析に役立てることができます。
データ統合のプロセスを理解し、実践することで、ビジネスインテリジェンスの向上に繋がるでしょう。


コメント