
データセットの役割と重要性
Azure Data Factory(ADF)において、データセットはパイプラインでデータをやり取りする際に欠かせない重要な構成要素です。データセットは、特定のデータストア内のデータ構造(例: ファイル、テーブルなど)を定義するもので、データの送受信や処理をスムーズに行うための「橋渡し」の役割を果たします。
データセットの主な役割
- データの場所を指定
データセットは、どこにデータが格納されているのか(Blob Storageの特定のフォルダやSQLの特定のテーブルなど)を明確にします。これにより、パイプラインやアクティビティが正確にデータへアクセスできます。 - データの形式を定義
データの構造(列名やデータ型)やフォーマット(CSV、JSON、Parquetなど)を指定します。これにより、データの処理時に期待される形が明確になり、エラーの発生を防ぎます。 - データフローでのマッピングを簡素化
データセットを使用することで、データフロー内でのスキーママッピングが簡単になります。これにより、データ変換や移動時の作業効率が向上します。 - 再利用性の向上
1つのデータセットを複数のパイプラインやアクティビティで再利用できるため、効率的で一貫性のあるデータ処理が可能になります。
データセットが重要な理由
データセットは、単なる「設定項目」ではなく、データ統合を設計する上での基盤です。適切にデータセットを構築することで、以下のような利点があります。
- 運用の効率化: データセットを再利用することで、開発時間を短縮し、運用の複雑さを軽減できます。
- エラーの防止: データセットでデータ構造を定義しておくことで、不整合や誤設定によるトラブルを未然に防げます。
- 保守性の向上: データの場所や形式が変更された場合でも、データセットを更新するだけで複数のパイプラインに影響を反映できます。
データセットは、ADFでのデータ統合プロジェクトを成功させるための「設計図」のような存在です。その重要性を理解し、適切に活用することで、データ処理の品質と効率を大幅に向上させることができます。
作り方
汎用性を高めるために、ディレクトリやファイルパスをパラメータとして渡せるように設定する方法を解説します。
このアプローチにより、同じデータセットを複数のパイプラインで使い回しでき、保守性や効率が向上します。
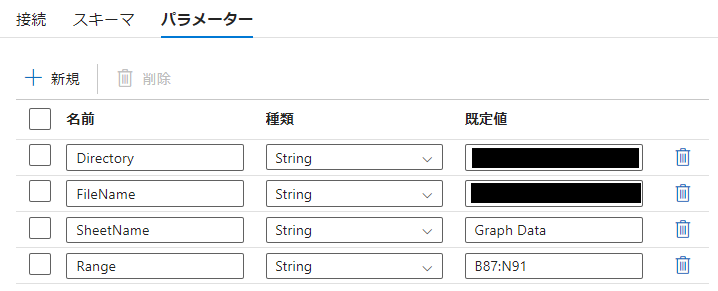
1. データセットにパラメータを追加
- データセットの「パラメータ」タブで、新しいパラメータを追加します。
- 例:
Directory(ディレクトリのパス)やfileName(ファイル名)のパラメータを定義。
エクセルファイルならRange(セル範囲)なども定義。
- 例:
- 必要に応じてデフォルト値を設定します。
2. ファイルパスを動的に設定
- データセットの「接続」タブで、ファイルパスやディレクトリの部分を編集します。
- ファイルパスやディレクトリを指定する箇所に動的コンテンツを設定します。
- 動的コンテンツの式は、パラメータを使用して構築します。
例:- ディレクトリ:
@dataset().Directory - ファイル名:
@dataset().fileName
- ディレクトリ:
- 動的コンテンツの式は、パラメータを使用して構築します。
- ファイル形式(CSV、JSONなど)やその他のプロパティも動的に設定可能です。

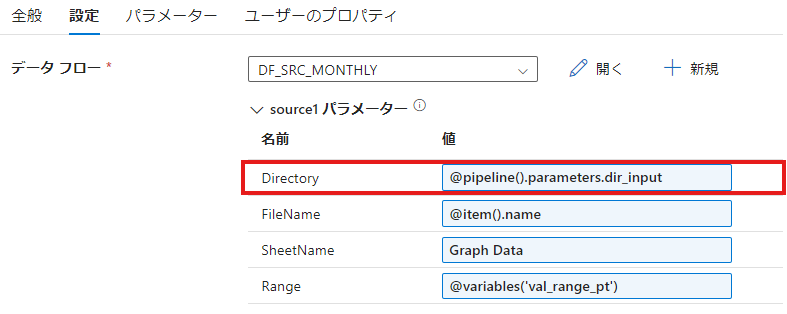
3. パイプラインからパラメータを渡す
- パイプラインでデータセットを参照するアクティビティ(例: Copy Activityやデータフロー)を設定します。
- アクティビティの「設定」タブで、データセットに渡すパラメータを指定します。
- 例:
directoryPath:@pipeline().parameters.dir_inputfileName:@pipeline().parameters.inputFileName
- 例:
- 必要に応じて、パイプライン側でパラメータを事前に定義しておきます。
メリット
- 柔軟性: パスが変更されてもデータセットを作り直す必要がない。
- 効率化: 汎用データセットを活用することで、パイプラインの再利用性が向上。
- 管理の簡略化: データセットを統一的に管理でき、運用負担が軽減。
パラメータを活用することで、データ処理の自動化やスケーラビリティがさらに向上します。

コメント